Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
정말정말 유명한 논문이고 다른 분들의 리뷰도 많기 때문에 지금 시점에 이 논문의 리뷰를 작성하는 의미는 잘 모르겠지만....
Object detection을 이용해서 풀어야할 문제가 생겨 YOLO 논문 정리부터 차근차근 시작해보고자 한다.
1. Intro
논문에서 제안하는 모델은 YOLO이다.
YOLO는 전체 이미지 픽셀로부터 Bounding box와 box 내의 각 클래스 확률을 예측하는 통합된 회귀 모델 구조를 이용해 object detection문제를 해결한다.
앞서 설명했듯 YOLO는 두 과정(bounding box 예측, class 추론)이 통합된 단일 네트워크로 구성되기 때문에 end-to-end 모델이다.
이 점은 모델의 학습과 최적화에 매우 큰 이점을 준다.
unified model인 YOLO의 장점은 다음과 같다.
- YOLO is extremely fast. YOLO는 앞서 말한 이유로 다른 모델에 비해 빠를 뿐만 아니라 다른 real-time 시스템과 비교해서 mAP가 두 배 이상 뛰어나다.
- YOLO reasons globally about the image when making predictions. YOLO는 한 번에 전체 이미지를 보기 때문에 contextual information 파악이 용이하다.
- YOLO learns generalizable representations of objects. 새로운 데이터에서 실험을 했을 때 좀 더 안정적인 성능을 보였다.
2. Unified Detection
YOLO는 다음의 두 과정을 하나의 단일 네트워크로 통합한 구조이다.
- 전체 이미지로 부터 각각의 bounding box를 예측하는 문제.
- 모든 bounding box에 대해 class를 예측하는 문제
YOLO의 작동방식
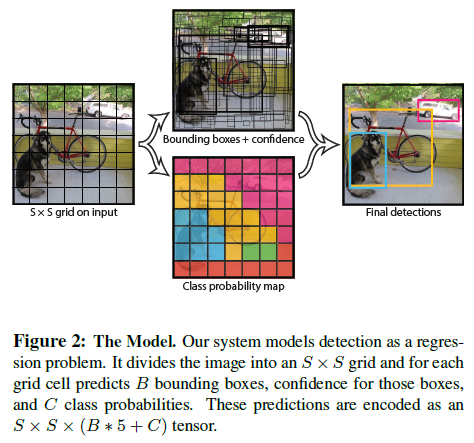
-
전체 이미지를 S x S 그리드로 나눈다. (예시는 7 x 7)
-
각각의 그리드에서 Bounding box를 예측하고 confidence score를 구한다. Bounding box 예측 Box의 중심 (x, y), 박스의 크기(w, h)를 예측한다. confidence score 모델이 예측하기에 bounding box 내에 object가 있음을 확신하는 정도 + 이런 확신의 정확성을 수치화한 점수.💡confidence score : - 그리드 안에 object가 없을 경우 : 0 - 그리드 안에 object가 있을 경우 : IOU between predicted box and truth
-
를 예측한다.
-
를 계산한다.
Network Design
24개의 Convolution과 2개의 Fully connected layer로 구성되어 있다.
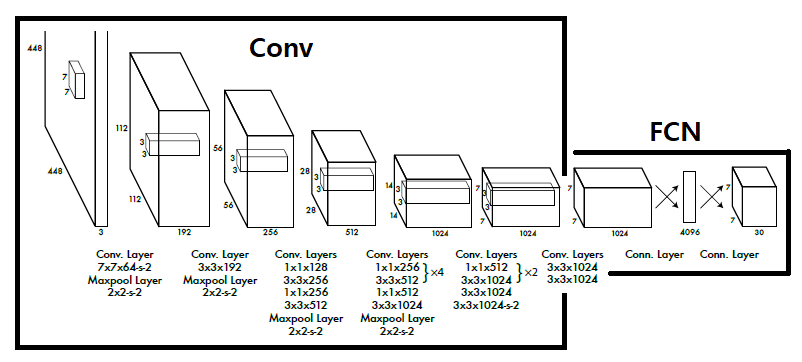
저자들의 말로는 모델의 구조는 GoogLeNet에 영향을 많이 받았지만 인셉션 모듈을 사용하지는 않고 1 x 1 reduction layer를 사용했다고 한다.
(Fast YOLO의 경우 24개의 Conv가 아닌 9개를 사용했다고 한다.)
Training
pretraining
초기 20개의 convolution layer를 ImageNet 1000-class competition dataset을 이용해 pretrain 시켰다.
이후에 랜덤하게 초기화된 convolution 4개와 fully connected layer를 추가해 최종 detection 모델을 학습 시켰다.
Resolution
Detection 이 때때로 fine-grained visual information를 요구하기 때문에 해상도를 224 × 224 에서 448 × 448로 증가시켰다.
Normalize
최종 layer의 아웃풋은 S x S X (B * 5 + C)가 된다.
C는 각 클래스의 확률을 의미하기 때문에 0 ~1 사이 값을 갖게된다.
B는 Bounding box에 대한 정보를 의미하는데 box의 중심 좌표, 높이, 너비 등을 갑 그대로 사용할 경우 loss function에서 scale 문제가 발생할 것이다.
따라서 normalize를 통해 값을 0 ~ 1사이가 되도록 조절하는 과정을 거쳤다.
Activation function
최종 Fully connected layer만 linear activation function을 사용했고 나머지 layer는 전부 leakt ReLU를 사용했다.
Loss function
최적화하기 가장 용이한 SSE (sum-squared error)를 사용했다.
하지만!!
SSE에는 몇 가지 문제가 있었기에 저자들은 몇 가지 수정을 거쳤다.
localization error vs classification error
모델의 아웃풋에 localization과 classification 값에 대한 예측이 모두 있기 때문에 단순 SSE는 이것들의 가중치를 같게 두는 것으로 볼 수 있다.
→ bounding box 좌표와 관련된 loss는 증가시키고 배경에서 confidence 예측에 대한 loss는 감소시키는 것으로 해결했다.
Large box vs Small box
box의 크기에 따라서 오차가 차지하는 비중의 차이는 다르다.
기본적인 SSE는 이 점을 고려할 수 없기 때문에 모델의 높이와 너비 예측을 단순히 높이와 너비 자체를 구하는 것이 아닌 루트를 취한 높이와 너비 값을 예측하는 문제로 변환해 해결했다.
multiple bounding box
이부분에 해당하는 논문 내용인데 한글로 해석하자니 상당히 모호해지는 거 같다. 더 정확한 이해를 위해서는 원문을 보자.
간략한 요약은 YOLO는 multiple bounding box를 예측하는 모델이라서 단순히 전체 예측을 하는 predictor하나를 학습하기는 매우 어려울 것이다.
따라서 논문의 저자들은 bounding box 수에 맞춰 다수의 predictor들을 생성하고 각 클래스를 예측하는 것에 서로 다른 특성을 갖게 하기를 원하는 것 같다.
최종적인 Loss function은 다음과 같다.
: if object appears in cell i
: the jth bounding box predictor in cell i is “responsible” for that prediction.
(위의 내용들을 보고 loss function을 보니 이해가 된다!)
Inference
항상 말했듯 다른 모델에 비해 YOLO는 정말 빠르다는 점을 강조한다.
object가 한 그리드 안에 쏙 들어갈 경우 bounding box는 하나로 매우 정확히 예측이 가능하다.
하지만 object가 너무 크거나 object가 다수의 그리드의 가장 자리에 위치할 때 너무 많은 bounding box가 생성될 수 있다.
이것을 해결할 방법은 Non-maximal supression이다.
Non-maximal supression [1]
Non-maximal supression은 다음과 같은 순서로 진행된다.
- 동일한 클래스에 대해 confidence를 정렬한다.
- 가장 confidence가 높은 bounding box를 기준으로 IoU가 threshhold를 넘는 bounding box를 제거한다.
- 제거되지 않은 box들 중에서 2번 과정에서 선정된 box를 제외한 이후 1~2 과정을 반복한다. (더 이상 후보 box가 남지 않으면 알고리즘을 종료한다.)
위의 과정을 진행할 경우 중복된 box들은 전부 제거되고 거리가 떨어져 있는 유의미한 box들만 살아남을 것이다.
Limitations of YOLO
-
YOLO imposes strong spatial constraints on bounding box predictions 이미지를 그리드로 나누는 작업은 어떻게 보면 매우 큰 제약일 수 있다. 이런 그리드는 object 사이의 간격에 매우 큰 제약을 줄 것이다. YOLO는 새 떼와 같이 작은 물체들을 도저히 구분할 수 없을 것이다.
-
it struggles to generalize to objects in new or unusual aspect ratios or configurations. 이건 YOLO만의 문제가 아닌 것 같다. data driven model의 피할 수 없는 숙명이 아닐까 싶다.
- Our model also uses relatively coarse features for predicting bounding boxes down sampling 같은 기법으로 인해 그렇다고 하는데 이 부분도 다른 모델들과 크게 차이가 없지 않을까 싶다.
- our loss function treats errors the same in small bounding boxes versus large bounding boxes. loss function에서 알 수 있듯이 prediction에서 Large box와 Small box의 크기 차이에서 오는 오차를 고려해 높이와 너비를 다르게 계산하긴 했다. 하지만 confidence계산에 이용되는 IOU 계산 등 크기 차이에서 발생하는 모든 오차의 scale 차이를 고려하지는 못했다.
3. Comparison to Other Detection Systems
비교 모델들의 특성은 정말 간략하게만 알아보면 좋을 거 같다.
DPM
sliding window approach를 사용하며 static features 추출, region 분류, bounding box 예측의 전 과정이 분리되어 있다.
→ YOLO는 위의 일련의 과정을 하나의 네트워크로 통합했고 더 빠르고 성능도 좋다.
R-CNN
Selective Search를 통해 potential bounding box를 생성한 후 Convolution network, SVM, linear model을 순차적으로 적용해 object detection을 진행한다.
각각의 모델들을 개별적으로 학습 시켜야 하기 때문에 최적화가 어렵고 속도가 매우 느리다.
→ potential bounding box를 제안하는 것과 Convolution을 이용해 feature를 추출하는 것에는 공통점이 있으나 그리드를 이용해 훨씬 적은 bounding box를 제안한다.
Fast & Faster R-CNN
R-CNN의 속도를 개선하고 성능 향상을 위해 제안된 모델들이다. 하지만 여전히 real-time object detection에 사용하기에는 부족하다.
Deep MultiBox
R-CNN의 Selective Search를 대신해 CNN을 이용해 RoI(regions of interest)를 구한다. MultiBox는 single object detection 밖에 할 수없으며 Multi object detection을 위해서는 multi object detection을 위한 complex pipeline의 일부분에 사용되는 방법밖에 없다.
OverFeat
CNN을 이용해 localization과 detection을 진행한다. OverFeat은 sliding window 방식을 매우 효율적으로 실행시키는 것은 맞지만 DPM과 같이 개별적인 모델을 이용한 방식이기에 한계가 명확하다.
또한, sliding window 방식은 image의 전체를 보는 방식이 아니기에 global context를 고려할 수 없다.
MultiGrasp
YOLO의 그리드 접근의 뿌리가 되는 기법이다. 하지만 MultiGrasp는 너무나 단순한 모델이다.
MultiGrasp는 단일 graspable region을 예측하며 single object를 위한 모델이다.
4. Experiments
Comparison to Other Real-Time Systems
다음 한 장의 그림으로 요약 가능하다.
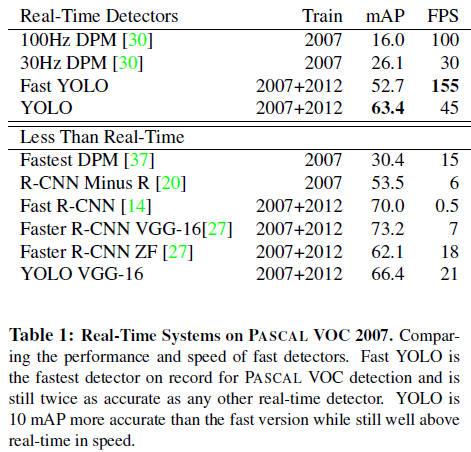
VOC 2007 Error Analysis
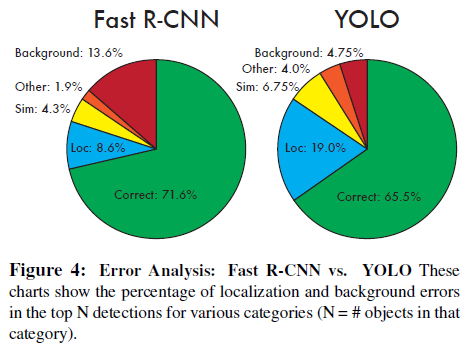
각 범주의 기준은 다음과 같다.
- Correct: correct class and IOU > .5
- Localization: correct class, .1 < IOU < .5
- Similar: class is similar, IOU > .1
- Other: class is wrong, IOU > .1
- Background: IOU < .1 for any object
YOLO는 Localization 비율이 상대적으로 높고 Background의 비율이 매우 낮다.
Combining Fast R-CNN and YOLO
YOLO의 background를 적게 잡는다는 점을 이용해서 Fast R-CNN과 결합한 구조의 성능을 검증했다.
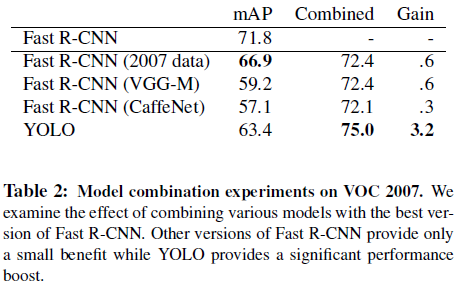
Fast R-CNN에 YOLO를 결합했을 때 Gain이 3.2로 가장 높았다.
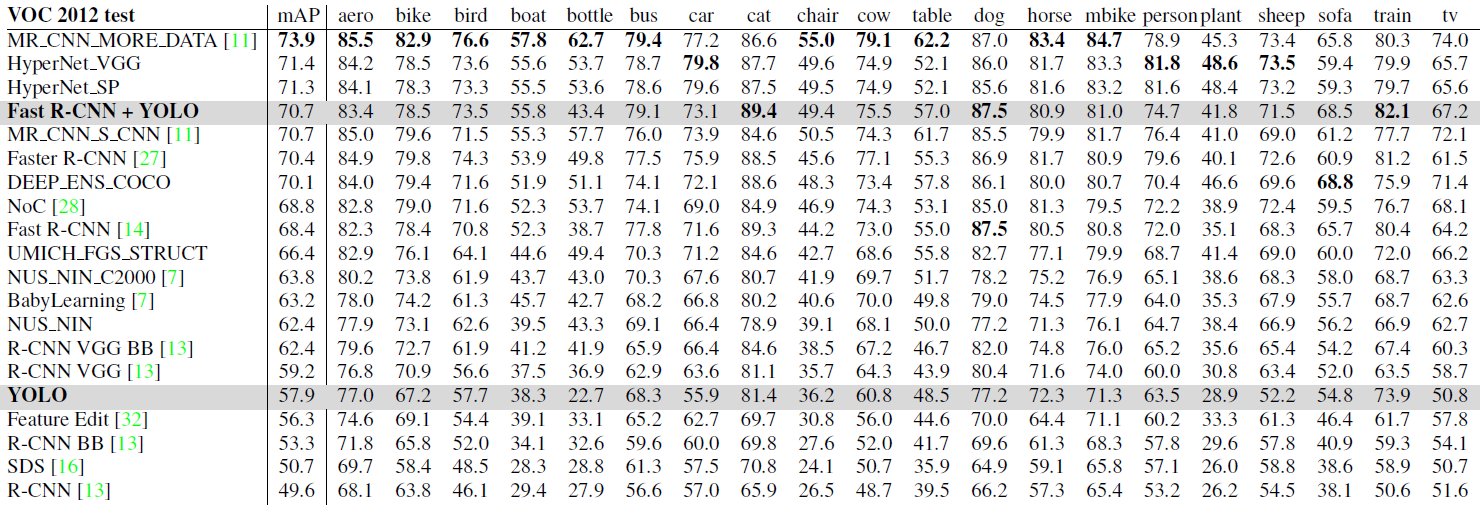
VOC 2012 Results
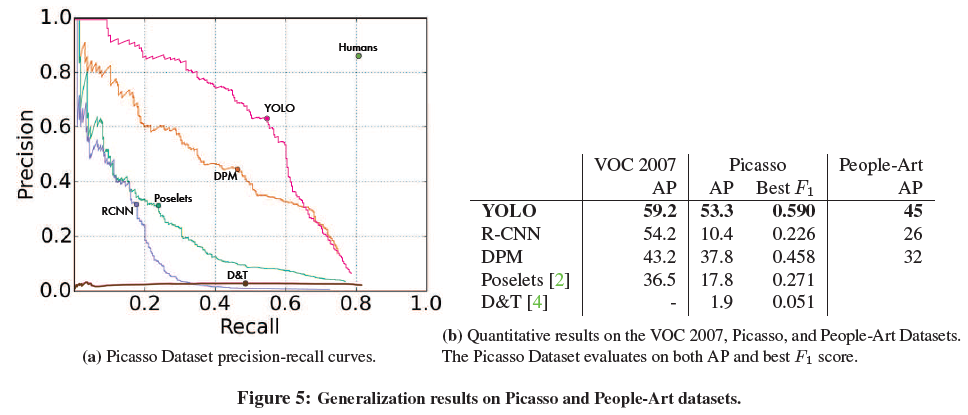
Generalizability: Persion Detection in Artwork

Reference