데이터 분석을 시작할 때 가장 흔히 사용하는 데이터의 형태는 xlsx, csv일 것이다.
파이썬 새내기 시절 xlsx 파일을 csv 파일로 바꾸는 것만으로도 엄청난 파일 로드 시간 혁신을 이룰 수 있었다.
하지만 분석의 경험이 쌓이고 데이터셋의 크기도 점점 커지다 보니 csv 데이터셋을 불러오는 것 역시 만족스럽지 않았고 더 좋은 파일 format에 대해서 찾아보게 되었다.
Stack overflow
What is the fastest way to upload a big csv file in notebook to work with python pandas?
세상의 모든 코딩 지식은 stack overflow에 있는 거 같다. 위의 답변을 보고 hdf란 확장자를 처음 알게 되었고 hdf를 통해 xlsx → csv 때 보다 훨씬 더 큰 효과를 볼 수 있었다.
하지만, 인간의 욕심은 끝이 없는지라 더 많은 format이 궁금해지기도 하고 상황에 따라 가장 효율적인 format을 직접 실험해 보고자 하는 욕구가 강력히 생겨났다.
pandas data format list
우선 pandas에 존재하는 모든 format에 대해서 실험을 진행했다.
'''
pd.to_csv, compression : {'infer', 'gzip', 'bz2', 'zip', 'xz', None}, default 'infer'
pd.to_json, orient : {'split', 'records', 'index', 'columns', 'values', 'table'},
default 'columns'
compression{'infer', 'gzip', 'bz2', 'zip', 'xz', None}, default 'infer'
pd.to_excel, None
pd.to_hdf, complib : {'zlib', 'lzo', 'bzip2', 'blosc'}, default 'zlib',
format : {'fixed', 'table', None}, default 'fixed',
pd.to_feather, None
pd.to_parquet, compression{'snappy', 'gzip', 'brotli', None}, default 'snappy'
pd.to_stata, None
pd.to_pickle, compression{'infer', 'gzip', 'bz2', 'zip', 'xz', None}, default 'infer'
'''
phm_data_challenge_2018 데이터셋에서 train/02_M01_DC_train.csv 파일을 이용했다.
파일 크기 : 1065 Mb
순위는 매우 주관적이지만 객관적이려 노력했으며 다음과 같은 사항을 중점적으로 고려했다.
- Write에 비해 Read가 훨씬 더 자주 일어나기 때문에 Read time이 훨씬 더 중요하다.
- size는 작을수록 좋다.
CSV
test_{compression}.csv
실험 결과를 알고 싶다면 click !!
Write time (sec)
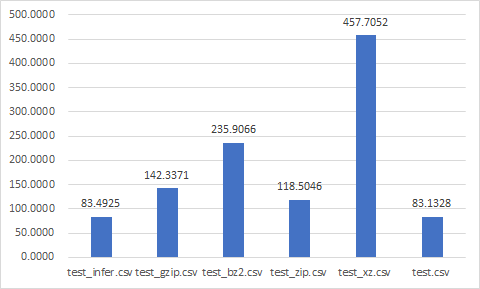
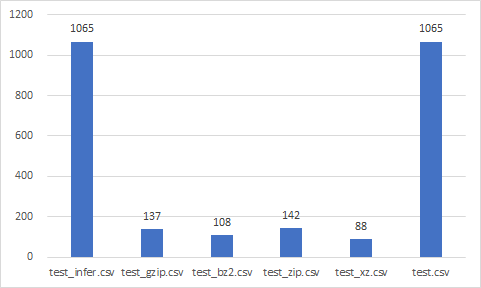
Data size (Mb)
Read time (sec)
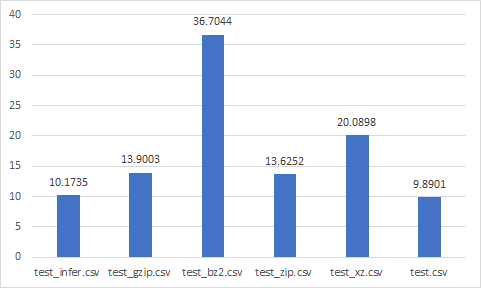
Best
- test_zip.csv
- test_gzip.csv
HDF
- test_{format}_{complib}.h5
- test_{complib}.h5 (format : None)
실험 결과를 알고 싶다면 click !!
Write time (sec)
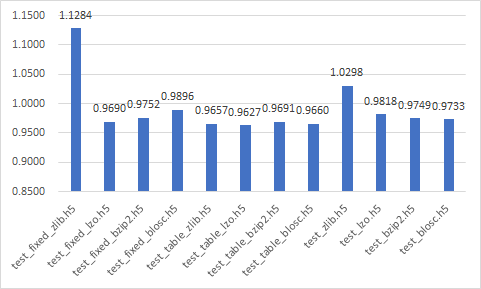
Data size (Mb)
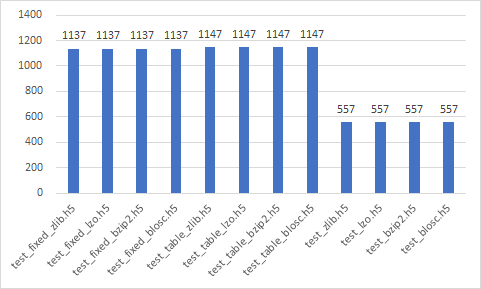
Read time (sec)
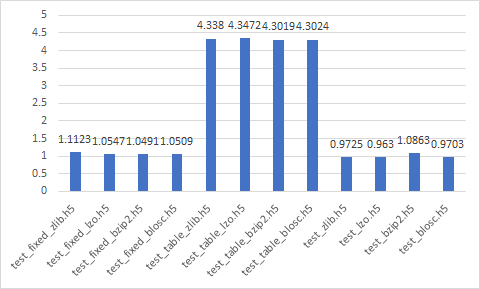
Best
- test_zlib.h5
- test_lzo.h5
- test_bzip2.h5
- test_blosc.h5
JSON
- test_{orient}_{compression}.json
- test_{orient}.json (compression : None)
실험 결과를 알고 싶다면 click !!
Write time (sec)
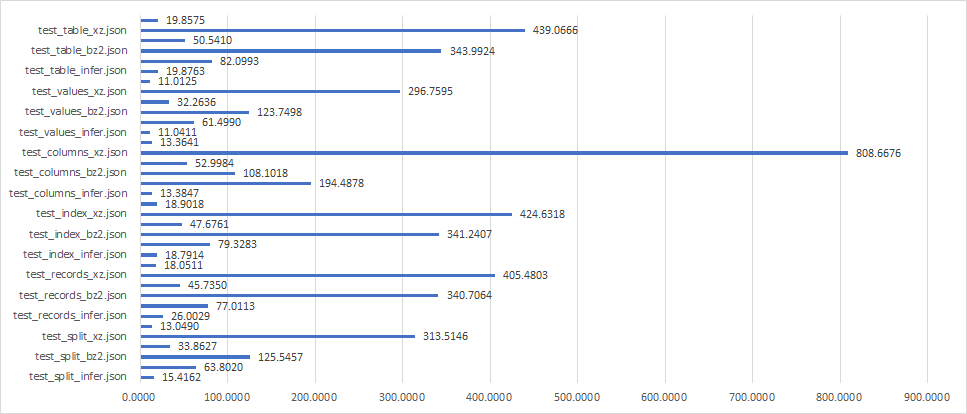
Data size (Mb)
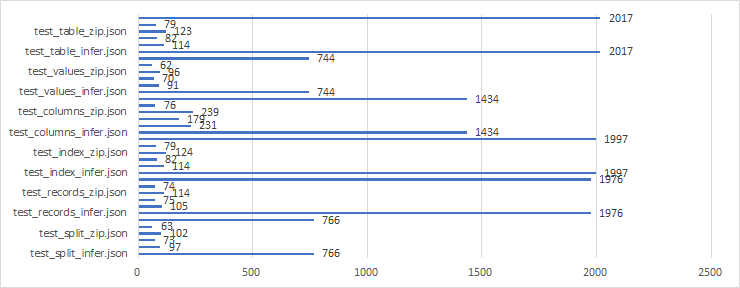
Read time (sec)
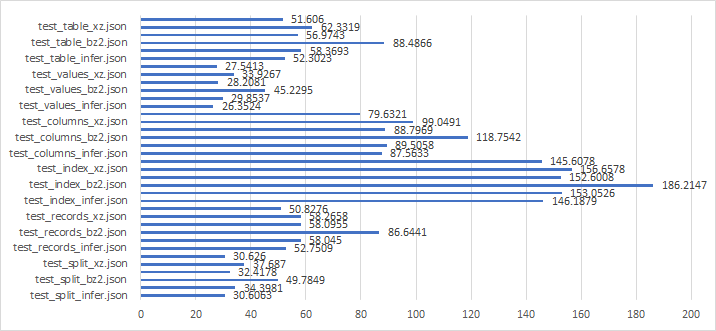
Best
- test_values_zip.json
- test_values_gzip.json
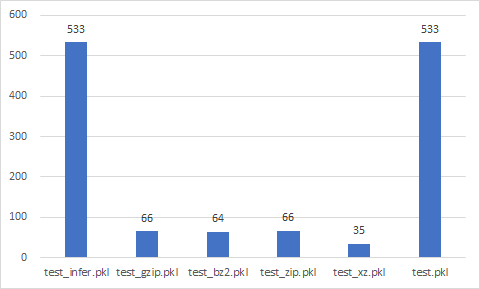
Pickle
test_{compression}.pkl
실험 결과를 알고 싶다면 click !!
Write time (sec)
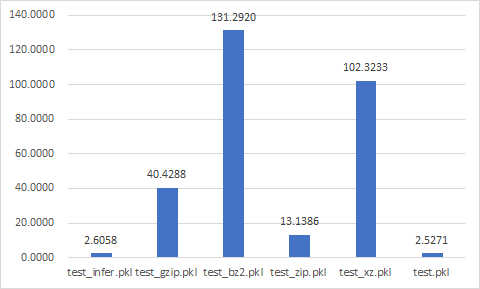
Data size (Mb)
Read time (sec)
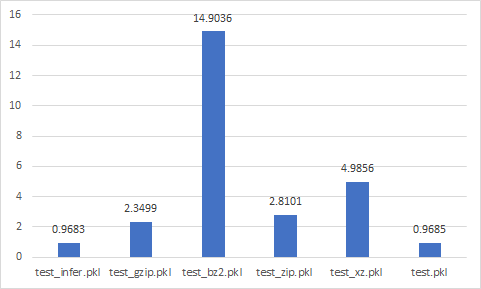
Best
- test_gzip.pkl
- test_zip.pkl
- test_xz.pkl
Others
test.ftr
test.dta
test_{compression}.parquet
실험 결과를 알고 싶다면 click !!
Write time (sec)
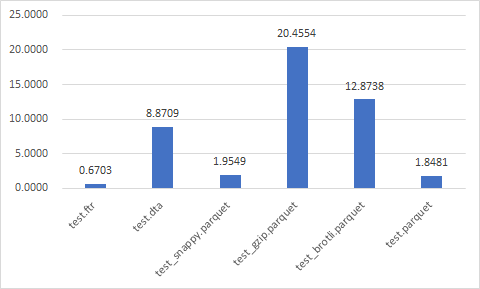
Data size (Mb)
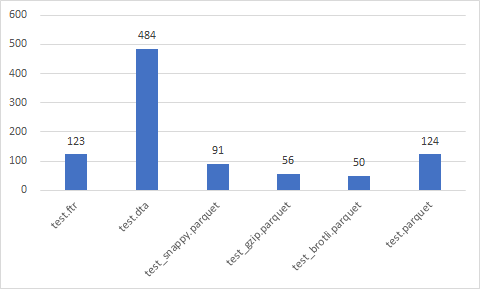
Read time (sec)
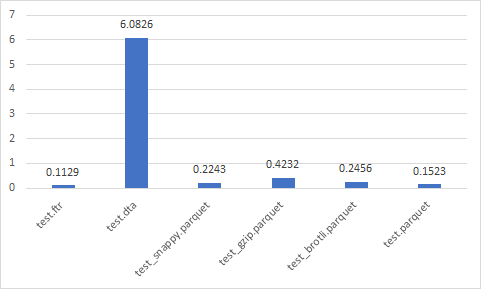
Best
- test_brotli.parquet
- test_snappy.parquet
- test.parquet
- test_gzip.parquet
- test.ftr
Best of the best format
json, csv, pkl format의 경우 read/write 시간에서 다른 format에 비해 경쟁력이 없다.
h5의 경우 data size에서 다른 format에 비해 경쟁력이 없다.
- test_brotli.parquet
- test_snappy.parquet
- test.parquet
- test_gzip.parquet
- test.ftr
에 대해서 파일을 50번 load한 시간의 합과 데이터 크기를 그래프로 나타냈다.
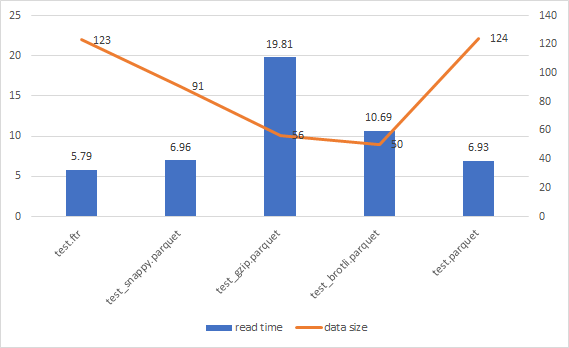
data size와 read time에는 분명한 trade-off 관계가 있음을 볼 수 있다.
로컬에서 사용할 경우
- 난 속도가 제일 중요하다. → ftr
- 난 용량이 제일 중요하다. → {brotli}.parquet
- 난 둘 다 중요해서 밸런스가 중요하다. → {snappy}.parquet
Load speed in AWS_s3
개인적으로 모든 데이터 파일을 AWS S3에 저장하고 있기 때문에
서버에서 파일을 불러오는 시간 + 데이터를 Dataframe (or array)로 바꾸는 시간의 합이 가장 작은 format으로 데이터를 관리하려고 한다.
(S3에 접속해 데이터를 불러오는 코드를 이미 짰는데 추후에 사용 방법을 블로그에 올릴 예정이다.)
S3 load + dataframe 생성까지 평균 시간
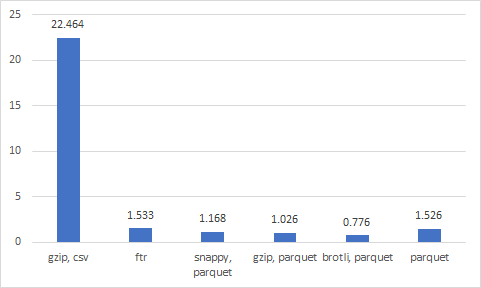
20번씩 테스트를 하였고 평균 시간을 나타냈다.
지금까지 gzip으로 압축한 csv 파일로 파일을 저장하고 있었는데 지금 당장 brotli parquet으로 바꿔야 겠다.
실험 코드에 대한 내용은 아래 깃허브에서 확인할 수 있습니다!!
