2015년에 나온 논문이라 Baseline과 trend가 지금과는 다소 다른 부분이 있다.
그럼에도 이번 논문을 리뷰하는 것은 Grad-CAM을 리뷰하기 위한 초석이며 해석가능한 딥러닝 모델을 공부함에 있어서 좋은 정보가 될 것이라 믿기 때문이다.
Introduction
Computer vision 에서 CNN이 다른 모델에 비해 압도적인 성능을 보이고 있다.
이는 Convolution layer이 그 구조상 localization에 뛰어난 능력을 갖기 때문이라고 설명된다.
Conolution layer만을 이용해서는 모델의 output size를 조절하는 작업이 쉽지 않기 때문에 이미지 분류같은 구체적인 task를 하기 위해 Convolution layer를 거친 이후 Fully connected network (FCN)를 연결하여 사용하고 있다.
문제는 여기서 발생하는데 FCN을 거치면서 Convolution layer의 localization 정보가 손실이 된다는 것이다.
이번 논문에서는 Computer vision에서 일반적인 task (Object detection or image classification) 모델의 localization 정보를 잃지 않으면서 task 성능은 거의 유사하게 유지하는 방법을 제안한다. 궁극적으로는 이런 localization 정보를 이용해 추가적인 task를 진행할 수 있음을 보인다.
Class activation mapping (CAM)
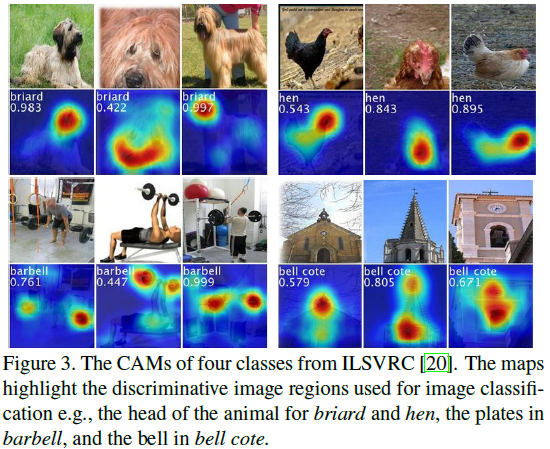
CAM은 특정 카테고리에 대해서 discriminative image region을 찾기 위한 도구이다. (Figure 3의 예시를 보자.)
그렇다면 CAM은 어떤 방식으로 구현이 되는가?
논문에서는 global average pooling을 이용해 CAM을 생성하는 모델을 제안한다.
global average pooling 개념
개별 feature map의 평균
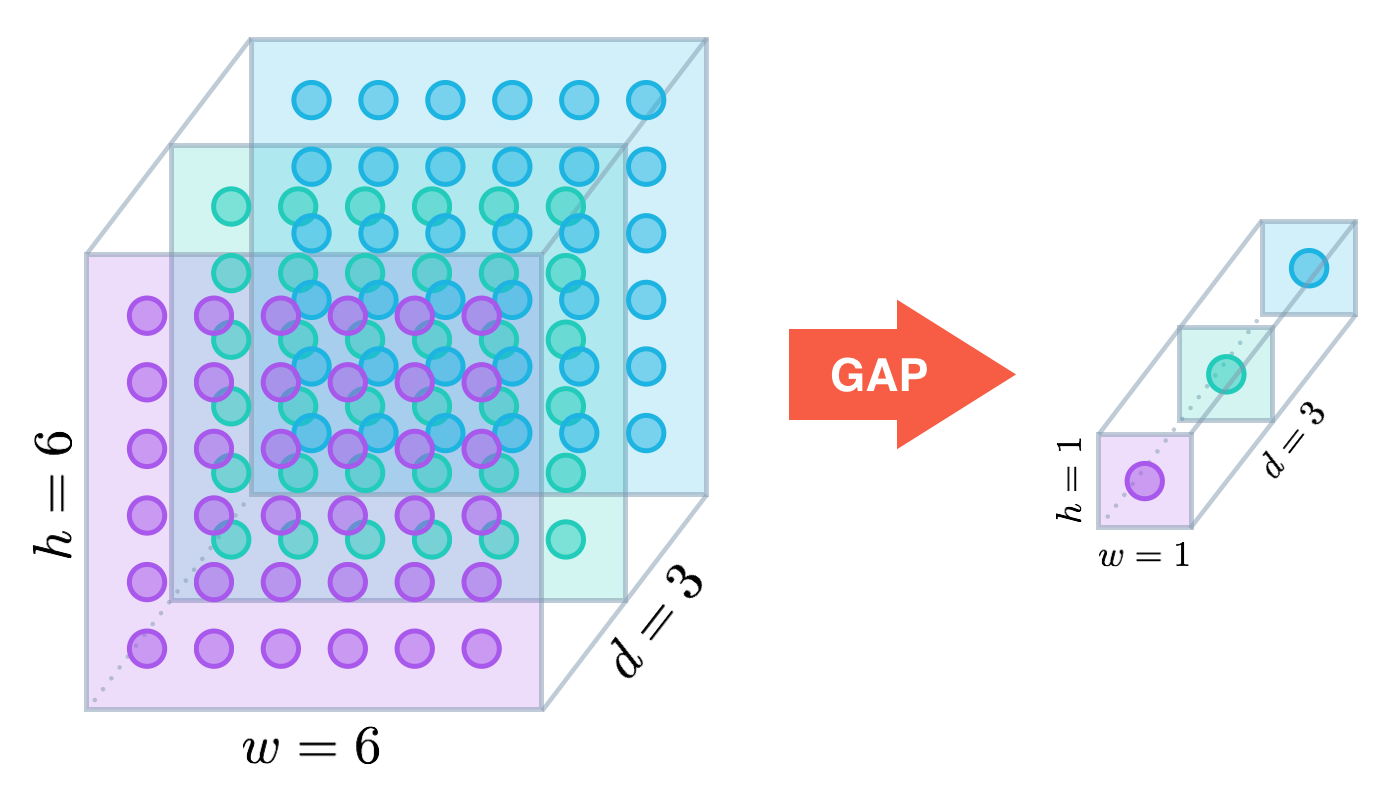
기존에는 global average pooling을 structural regularizer의 역할로 썼다면 이번 논문에서는 localization ability를 갖게 하는 도구로 사용한다.
CAM을 생성하는 방법
CAM은 CNN을 사용하는 많은 Image classification model의 FCN 부분을 Global average pooling으로 대체함으로써 다양한 모델에서 쉽게 생성할 수 있다.
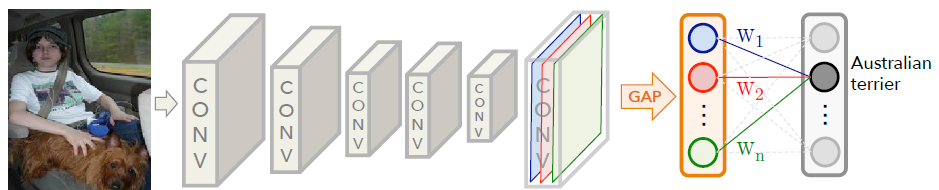
마지막 Convolution layer에서 나온 feature map을 global average pooling 한 이후 한 층의 FCN을 이용해 분류 작업을 진행한다.
이후의 CAM을 만드는 원리에 대한 설명을 위해 조금 더 자세히 설명하자면
Global average pooling을 이용해 나온 feature map의 평균값과 해당하는 class 사이의 weight을 곱해 합한 값이 해당 class에 대한 최종 output이된다.
CAM을 생성하는 과정도 이와 유사하다.
논문에서 CAM을 설명하는 구체적인 수식은 아래와 같다.
- global average pooling
: k번째 feature map에서 x, y 좌표가 갖는 값
map의 size가 동일하기 때문에 단순 합과 평균의 의미가 같기에 단순 합으로 표기한 것으로 보인다.
2. class score
: class c에 해당하는 node의 weight 중 k번째 feature map과 상응하는 weight
3. importance of the activation at spatial grid (x, y)
class score는 다음과 같이 표현할 수도 있다.
importance of the activation at spatial grid (x, y)를 다음과 같이 정의한다.
CAM의 가중합을 위한 weight을 결정하는 요인은 class와 feature map 뿐이다.
그림과 식에서 알 수 있듯이 특정 Class에 대해서 feature map과 weight이 1대1로 대응하기 때문에 CAM의 구성은 다음 그림 한 장으로 설명이 가능하다.

은 <Global average pooling 분류 모델>의 weight과 동일하다.
Global average pooling (GAP) vs Global max pooling (GMP)
CAM을 구현하는 방법은 알게 되었지만 한 가지 궁금한 점이 있다.왜 Average를 사용하는 것인가?
가장 중요한 이유는 GAP가 GMP보다 성능이 높다는 것이다.
deep learning model의 한계로 성능이 높은 이유를 구체적으로 설명을 할 수는 없다.
논문에서는 Average가 discriminative part 전체를 고려할 수 있다면 Max는 discriminative boundary같이 극단적으로 변하는 부분을 크게 반영하기에 다른 세부적인 차이를 반영할 수 없다고 믿는다. (물론 믿음이다.)
Weakly-supervised Object Localization Result
이번 논문에서 localization을 위해서 bounding box가 정의된 데이터 셋을 이용하지 않는다. (bounding box가 정의된 데이터라고 하더라도 bounding box 정보를 이용하지 않는다.)
imagenet dataset과 같이 bounding box가 구비된 데이터 셋은 현실에서 매우 적기 때문에 bounding box를 이용해서 모델을 학습하는 것은 현실에서 매우 어렵다.
따라서, image의 label을 분류하는 모델을 학습하는 것만으로도 Object localization 기능을 추가적으로 하는 weakly-supervised object localization 방법을 이용한다.
setup
2015년 당시 유명했던 모델의 FCN 부분을 GAP로 바꿈으로써 CAM을 구현한다. 사용한 모델과 baseline 모델은 다음과 같다.
Classification & Localization performance
Classification
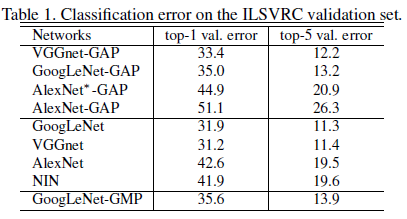
classification의 성능은 약간의 감소를 보인다.
weakly-supervised Localization baseline
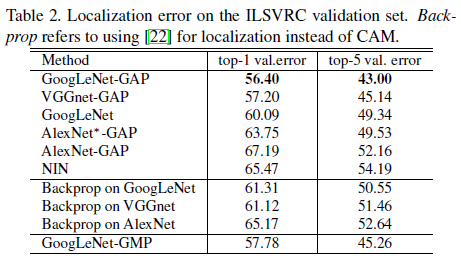
weakly-supervised localization baseline 모델보다 더 우수한 성능을 보인다.
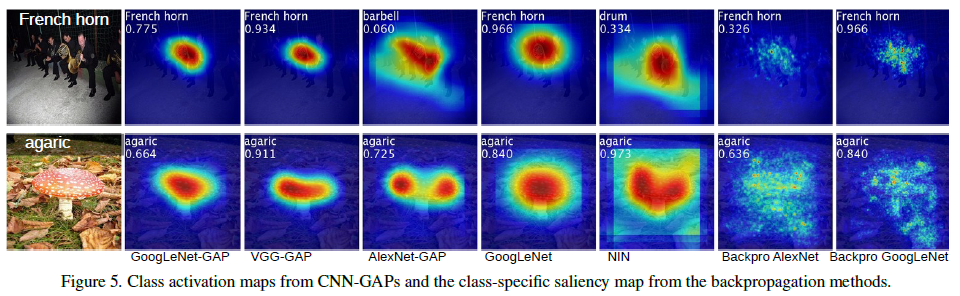
실제 예시를 통해 localization의 activation map을 비교해보면 GAP을 이용한 모델이 좀 더 label의 의미에 가까운 부분을 포착하는 것을 확인할 수 있다.

fully-supervised localization baseline

fully-supervised 모델에 비하면 성능이 다소 떨어지긴 하지만 AlexNet과 거의 유사한 수준의 성능이 나옴을 확인할 수 있다.
Deep Features for Genenric Localization
아래의 그림은 CAM을 통해 얻은 Deep feature의 generic localization 성능이 우수함을 보이는 예시이다.
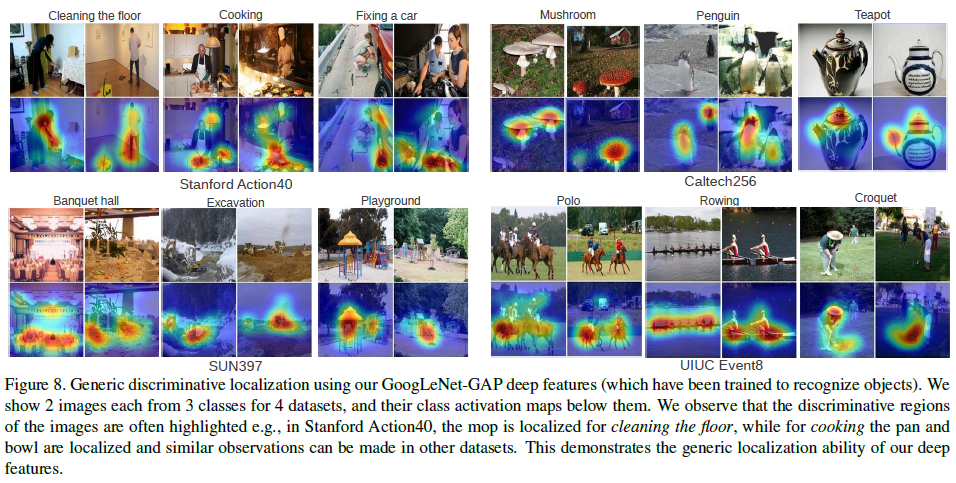
논문에서는 CAM을 이용해서 다양한 문제들을 풀었다. 아래는 그것들의 예시이다.
Discovering informative objects in the scenes

Concept localization in weakly labeled images

Weakly supervised text detector

Interpreting visual question answering
