Liu, Fei Tony, Kai Ming Ting, and Zhi-Hua Zhou. "Isolation forest." 2008 Eighth IEEE International Conference on Data Mining. IEEE, 2008.
기존 이상 탐지 방식
normal에 대한 profile을 생성한 이후 profile에 부합하지 않는 데이터에 대해서 비정상으로 분류
기존 방법의 결점 두 가지
- 모델을 만들 때 정상의 profile을 생성하기 위해 모델을 적합하기 때문에 false alarm이 너무 많음.
- 작은 사이즈, 저차원의 데이터에 국한됨.
Isolation Forest
본 논문에서는 새로운 model-based 이상 탐지 방법을 제안한다.
모델에서 집중하는 anomaly의 특성은 다음과 같다.
- 수가 적다.
- 정상과는 다른 특성을 갖는다.
isolation 의미
separating an instance from the rest of the instances
anomaly의 특성은 Isolation tree 학습 중 root node 근처에서 anomaly가 isolation되게끔 한다.
Isolation Forest의 특성
-
sub-sampling을 통해서 partial model을 만든다.
Isolation Forest를 이용한 이상 탐지 문제에서 주요한 어려움은 다음과 같다. Swamping : normal이 anomaly의 너무 근처에 위치할 경우, False alarm의 비율이 증가하게 됨. Masking : anomaly의 클러스터가 너무 크고 조밀할 경우, anomaly 자체를 isolate하기 위해 너무 많은 partioning이 필요함.
subsampling을 통해서 위의 두 가지 문제를 해결할 수 있다.
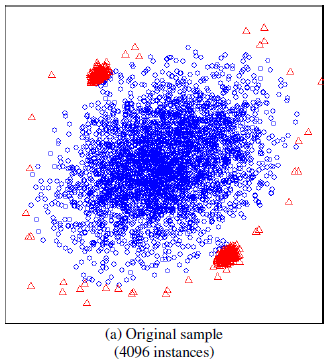
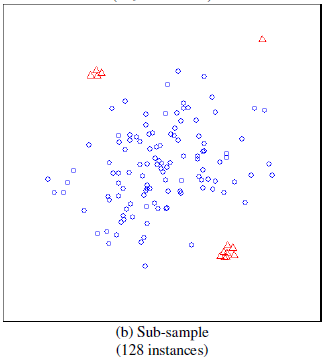
-
거리나 밀도에 대한 가정을 하지 않기 때문에 계산 복잡성이 낮다.
Isolation Forest는 Linear time complexity를 가지며 낮은 메모리를 필요로 한다. 따라서 큰 데이터와 고차원 데이터 역시 다룰 수 있다.
-
Anomaly score
iTree 별로 가능한 maximum height의 값이 다르기 때문에 Path length의 단순 평균을 Anomaly score로 하는 것은 좋지 않다. Normalized Score를 만들기 위해 Binary Search Tree의 unsuccessful search 평균 path 길이를 추정하기 위해 사용되는 다음 식을 이용한다.
n개의 sample이 주어졌을 때,
: the harmonic number
최종적으로 Anomaly score는 다음과 같다.
Isolation Forest의 작동 원리
모든 instance가 isolation 될 때까지 반복적으로 partitioning 진행할 경우, anomaly에 대해서 짧은 path (root node부터 최종 external node까지 거친 edge의 수)를 생성할 것이다.
why?
- the fewer instances of anomalies result in a smaller number of partitions
- instances with distinguishable attribute-values are more likely to be separated in early partitioning.
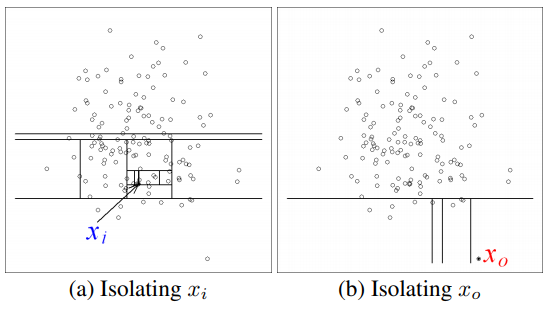
Isolation Tree partitioning 종료 조건
- 미리 지정한 Tree의 height 한도에 도달할 경우.
- Node에 속한 데이터가 하나일 경우.
- Node에 속한 데이터가 모두 같을 경우.
Anomaly detection을 위해서 Isolation Forest는 Training Stage, Evaluating Stage 두 단계를 거친다.
-
Training Stage : 종료조건을 만족할 때까지 partitioning을 진행하여 iTree를 생성한다.
: sub-sampling size (default : 256)
: tree의 수 (ensemble size, default : 100)


-
Evaluating Stage : path length로 부터 anomaly score를 계산한다.
아래의 PathLength function을 이용해 h(x)를 계산한 이후 anomaly score 식을 이용해 최종 score를 구한다.

실험 결과
데이터셋
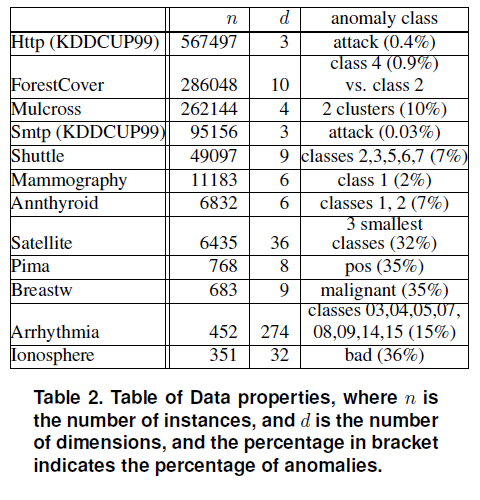
ORCA, LOF, RF와 비교
ORCA : k-Nearest Neighbour (k-nn) based method
LOF : density based method
RF : Random Forest