Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization
21 Aug 2020
Reading time ~4 minutes
CAM 논문을 읽었다면 Grad-CAM을 읽게 되는 건 어떻게 보면 당연할지도....
Introduction
이번 논문에서 제안하는 모델은 Gradient-weighted Class Activation Mapping (Grad-CAM)이다.
CAM 논문을 읽었다면 벌써 어떤 목적으로 이 모델을 제안했는지 알게 될 것이다.
CAM 논문을 읽지 않았다면 아래 링크에서 먼저 보고 오자!
Computer vision에서 CNN의 성공은 Deep learning의 폭발적인 관심을 불러일으켰지만 여전히 설명력의 부족이라는 한계를 가지고 있다.
저자들은 모델이 설명력을 가져야 하는 이유를 사람과의 상호작용에서 찾고 있다.
- when AI is significantly weaker than humans and not yet reliably ‘deployable’
→ 모델이 왜 성능이 낮은지 알기 위해
- when AI is on par with humans and reliably ‘deployable’
→ 모델의 신뢰도를 얻기 위해
- when AI is significantly stronger than humans
→ 인간이 AI에게 배우기 위해
사실 설명력이 중요한 이유는 너무나 명확하기 때문에 모두가 그 중요성을 인지하고 있다.
하지만, 왜 Deep learning 모델은 설명력을 갖지 못할까?
일반적으로 모델의 복잡성(≈ 성능)과 모델의 설명력은 trade-off 관계에 있기 때문이다.
GPU의 발전은 Network의 깊이를 더욱 깊게 만들었고 모델의 성능을 얻은 대신 설명력을 잃어버렸다.
이번 논문의 이야기로 돌아와서 CAM의 경우를 보자.
CAM의 경우, 모델의 마지막 Fully connected layer를 Global average pooling으로 바꿔 모델을 단순화시켰다.
이런 변형으로 설명력을 얻었지만 기존 모델의 성능에 비해 다소 떨어진 성능을 보였다.
모델의 구조를 바꾸는 것은 필연적으로 모델의 성능 저하를 일으킨다.
따라서 저자들은 모델의 구조를 전혀 바꾸지 않으면서 설명력을 가지게 하는 방법을 제안한다.
What makes a good visual explanations?
Computer vision에서 모델의 설명력이 가져야할 좋은 특성은 다음과 같다.
-
Class discriminative : 모델의 설명력은 Class에 따라 구별되는 특성을 보여야 한다.
아래의 그림은 Class discriminative 특성을 갖고 있지 않다.

좋은 Class discriminative 특성을 가진 모델은 다음과 같이 구별적인 설명이 가능해야 한다.

순서대로 Cat, Dog
-
High-resolution : 모델의 설명력은 fine-grained detail도 포함해야 한다.
모델이 아무리 설명을 잘할지라도 resolution이 너무 낮다면 인간이 사용하기에 유의미한 결과를 도출하기가 어렵다.
Gradient-weighted Class Activation Mapping (Grad-CAM)
Grad-CAM은 CAM의 일반화 모형이라고 저자들은 설명한다.
Grad-CAM은 마지막 Convolution layer의 feature map에 class에 따른 gradient를 곱해 이미지 분류를 위해 중요한 부분에 대한 localization map을 구한다.
구현 방법
notation
: 마지막 convolution layer의 k번째 feature map ( : width, : height)
: Label c 예측에 대한 score
: k번째 feature map의 (, ) 좌표의 값
Grad-CAM을 계산하는 방법은 크게 두 가지 과정으로 나뉜다.
- Feature map weight 구하기.$$\alpha_{k}^{c}=\frac{1}{Z} \sum_{i} \sum_{j}\frac{\partial y^{c}}{\partial A_{i j}^{k}}$$
feature map의 gradient 값을 모두 더해 feature map의 weight을 구한다.
- feature map의 각 점에서 중요도 찾기 (최종 localization map)$$L_{\mathrm{Grad}-\mathrm{CAM}}^{c}=\operatorname{ReLU}\left(\sum_{k} \alpha_{k}^{c} A^{k}\right)$$
feature map의 동일 위치 점에 대해서 각 feature map의 weight을 곱한 후 더한다.
더해진 값을 ReLU 함수에 넣는다.
Why ReLU?
ReLU의 효과는 score를 증가시키기 위해 더해야 하는 항목의 gradient만 남기는 것이다.
ReLU를 하지 않을 경우, 음의 값을 갖는 값들 역시 localization map을 구할 때 강조가 되기 때문에 더 명확한 해석력을 위해 음수값들을 전부 0으로 바꿔준다.
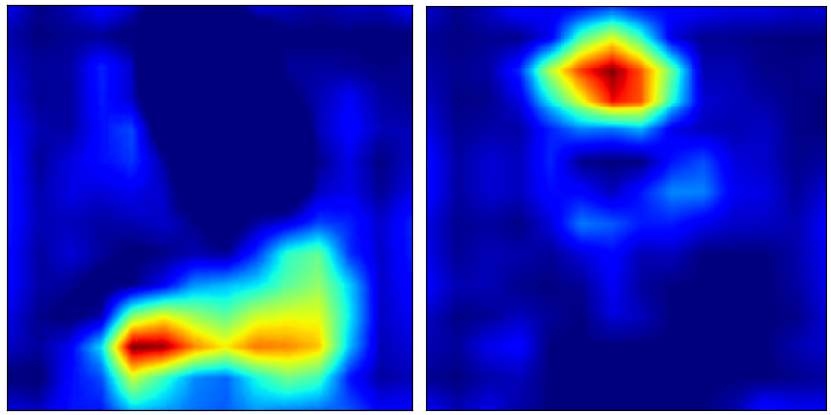
Grad-CAM의 결과 예시
label 'Cat'에 대해서 Grad-CAM을 실행하면 다음과 같은 결과를 얻을 수 있다.

고양이가 있는 위치를 Grad-CAM을 통해서 명확히 찾을 수는 있었지만 한 가지 부족한 점이 있다.
좋은 해석력이 가져야 하는 조건에 우리는 High-resolution에 대해서 언급한 적이 있다.
하지만, Grad-CAM은 High resolution 조건을 만족하지 못한다.
이것은 Grad-CAM이 최종 Convolution layer의 feature map에 대해서 실행되기 때문이다.
Grad-CAM의 output은 필연적으로 feature map의 크기와 같다.
일반적으로 Convolution layer 통해서 input의 크기가 점점 줄어드는 것을 생각해보면 Grad-CAM의 low-resolution이 이해가 될 것이다.
이런 단점을 극복하기 위해서 나온 구체적인 방법이 Guided Grad-CAM이다.
Guided Grad-CAM
Grad-CAM의 low resolution 문제를 해결하기 위해 Guided Backpropagation을 도입한다.
Guided backpropagation
우선 Guider backpropagation에 대해서 먼저 보자.
Forward pass의 activation function를 ReLU라고 하자.
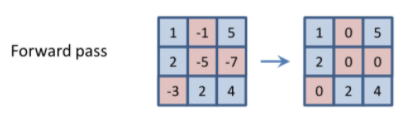
backpropagation은 forward pass의 ReLU output이 양수인 부분에 대해서만 학습이 진행된다.
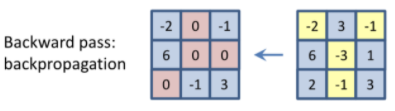
deconvnet에서는 gradient가 양수인 부분에 대해서만 학습이 진행된다.
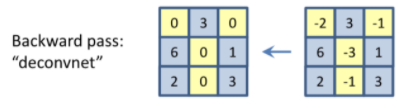
마지막으로 Guided backpropagation은 ReLU output과 gradient가 모두 양수인 부분에 대해서만 학습이 진행된다.

Guided Grad-CAM을 얻는 방법
Grad-CAM과 Guided backpropagation을 이용해서 Guided Grad-CAM을 얻는 구체적인 방법을 알아보자.
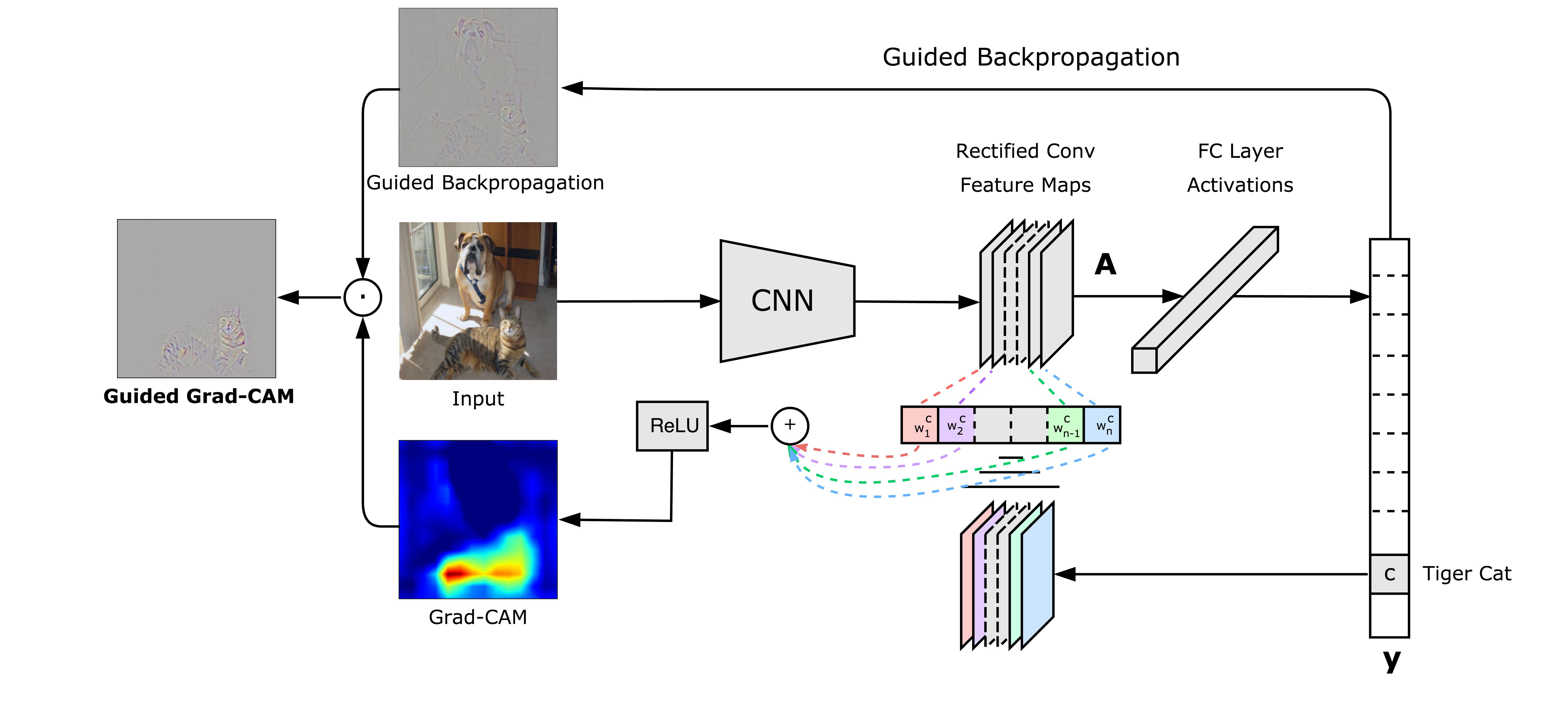
- Guided Backpropagation을 구한다.
- bi-linear interpolation을 이용해 Grad-CAM을 Up-sampling한다.
- Guided Backpropagation과 Up-sampled Grad-CAM을 pointwise multiplication을 통해서 Guided Grad-CAM을 구한다.
Experiments
Intro에서 AI와 인간의 상호작용을 위해 설명력이 필요함을 강조했다.
그래서 다음 실험 결과에 매우 흥미를 느낄 수 있었다.
설명력이 뛰어난 모델은 모델의 예측이 틀린 이유를 사람이 납득할 수 있게 설명해야 한다.
아래는 논문에 실린 오답에 대한 예시와 왜 모델이 이런 예측을 했는지 유추할 수 있는 Guided Grad-CAM 결과를 포함하고 있다.


결과들은 매우 흥미롭다. 모델이 Ground truth와는 다른 예측을 했지만 인간이 보기에도 이렇게 예측하는 것이 그렇게 틀리지는 않았다는 생각이 드는 사례가 많다.
(이렇게 Labeling 중요성을 또 한 번 배우고 간다...)
Reference
[1] Springenberg, Jost Tobias, et al. "Striving for simplicity: The all convolutional net." arXiv preprint arXiv:1412.6806 (2014).