Fault Detection and Diagnosis Using Self-Attentive Convolutional Neural Networks for Variable-Length Sensor Data in Semiconductor Manufacturing
06 Jul 2020
Reading time ~4 minutes
연구실 선배가 작성한 논문이라 코드와 함께 볼 수 있어 이해하기 편했던 것 같다.
Intro
- 반도체 공정같이 wafer가 순차적으로 들어와서 작업하는 연속 공정에서는 초기에 이상을 탐지하는 것으로 이후에 연속적인 defective wafer의 발생을 막을 수 있다.
- 최근에는 기기의 다양한 센서를 통해서 multivariate time-series data(SVID : Status variables identification)가 쏟아져 나오고 있다.
이상 탐지에 대한 니즈와 이런 대량 센서 데이터가 맞물려 data-driven fault detection이 떠오르고 있다.
이상을 탐지하는 방법의 단계는 다음과 같다.
- eyeball investigation 전문 작업자들이 raw data에서 비정상적인 패턴을 감지한다.
- FDC FDC 데이터를 이용해 작업자들이 하는 비정상 패턴 감지 작업을 자동화한다.👉FDC data feature extraction에 의해 만들어진 condensed data
condensed 데이터인 FDC 데이터는 다음과 같은 문제가 있다.
- feature extracion 과정을 거치며 데이터의 중요 정보가 사라질 수 있다.
- 센서 데이터의 시간축이 사라지기 때문에 diagnosis 시에 문제가 발생한 시점을 찾을 수 없다.
- fault detection directly from SVID (Status variables identification) SVID 데이터를 바로 사용하는 것은 FDC 방법에서 발생하는 2가지 문제점을 해결할 수 있다. 하지만!, SVID 데이터는 작업 시간이 wafer마다 다르기 때문에 일반적인 분석 방법을 적용하는 것에 어려움이 있다.
논문에서는 이런 어려움을 self-attention 알고리즘을 이용해 해결한다.
self-attention을 이용한 모델은 총 세 가지의 이점이 있다.
- attention score를 제공함으로써 모델의 fault detection 성능 향상을 돕는다.
- 다양한 input sequence 길이를 큰 시간 변화없이 처리할 수 있는 모델이다.
- attention score는 fault diagnosis를 위한 힌트를 제공한다.
Related Work
: 시간 : 센세 데이터 변수
Fault Detection and Diagnosis
FDC 데이터를 이용해 분석한 모델
Unsupervised model
차원 감소 알고리즘을 통해 outlier detection 성능을 높이는 경우가 많다.
- PCA (principal component analysis)
- GMM (gaussian mixture model)
- one-class SVM (support vector machine)
Supervised model
- SVM (support vector machine)
recursive feature elimination과 함께 진행.
- KNN (k-nearest neighbors)
- DT (decision tree)
- CNN kernel의 weight을 이용해 contribution level of the variable (CLV)를 계산해 feature의 중요도 rank를 제공함.
Deep learning-Based Sequence Classification Models
크게 RNN과 CNN 두 가지로 나뉜다.
RNN
- sequence 데이터에 특화된 network
- LSTM 대표적인 RNN 계열의 모델
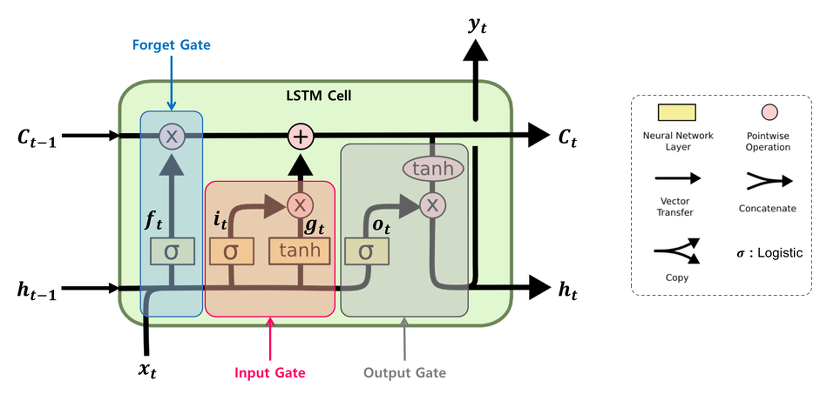
CNN
- 그리드 형태의 데이터 분석에 특화된 network
- 센서 변수들 간의 correlation을 반영하기 위해서 시간 축으로만 이동하는 sliding window 방식을 적용.
: 시간축의 kernel size
: Stride
Variable-Length Sequence Encoding Methods
RNN
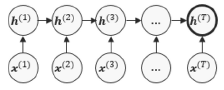
RNN의 마지막 hidden state만 사용.
마지막 hidden state가 sequential정보를 모두 가져야 한다는 어려운 점이 있다.
RNN + pooling
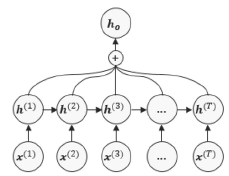
RNN의 모든 hidden state를 합해서 사용.
가장 간단한 방법은 단순 summation이다.
단순 합산을 하기 때문에 noise나 무관한 정보를 포함할 가능성이 높다.
RNN + self-attention
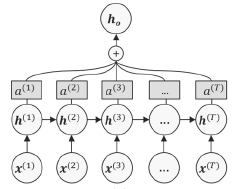
RNN + pooling의 문제점을 해결하기 위한 방안으로 self-attention mechanism을 이용.
: hidden state의 개수와 같은 차원을 갖는 벡터를 이용.
최종 output은 다음과 같다.
CNN + pooling
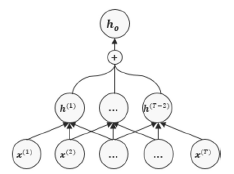
다양한 길이를 갖는 데이터를 sliding window 방식으로 feature 맵을 생성한 이후 hidden state를 합해서 사용.
The proposed Model
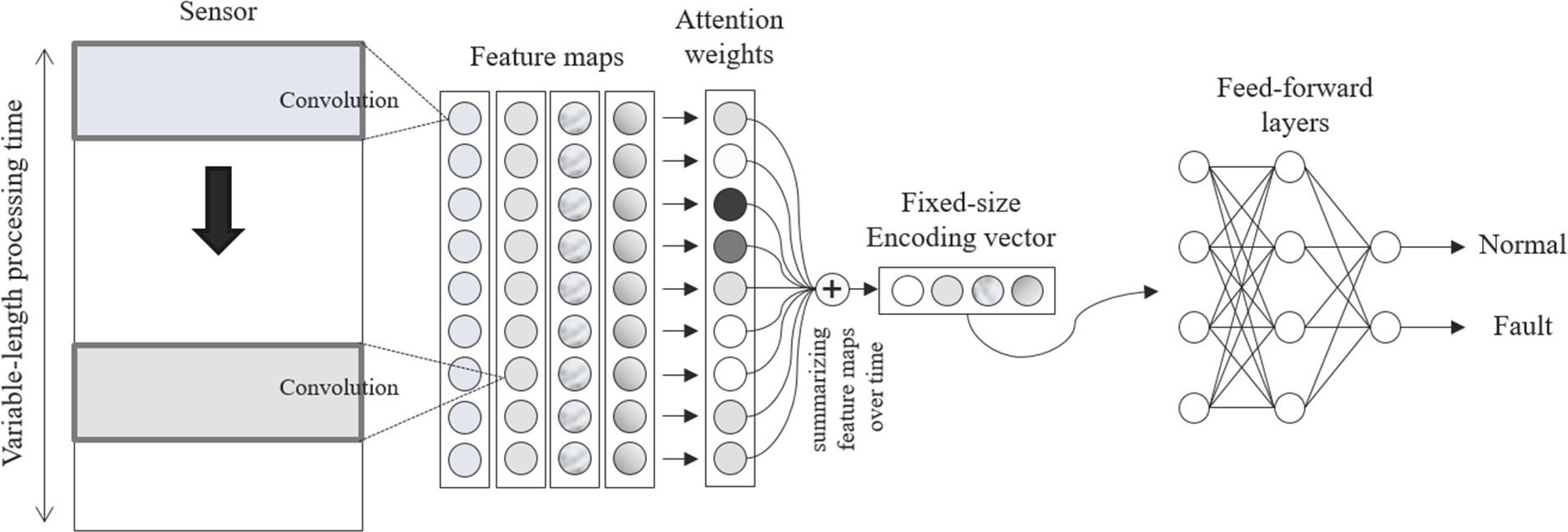
제안하는 모델은 위와 같으며 크게 3가지의 구조로 나눌 수 있다.
-
Feature extraction network CNN을 이용해 시계열 데이터의 Feature extraction을 실행한다. 시간이 T인 센서 데이터에 필터의 크기가 F인 K개의 필터를 사용한다면 최종 feature map은 다음과 같이 나타낼 수 있다.$$\boldsymbol{H}=\left(\boldsymbol{h}^{(1)}, \cdots, \boldsymbol{h}^{(T-F+1)}\right)=\left(f_{1}, \cdots, f_{K}\right)^{\top}$$
-
Self-attention mechanism self-attention mechanism을 이용해 위에서 구한 벡터를 fixed-size의 vector로 변환하는 작업을 거친다. attention score는 시간 축에 대해서 합이 1인 분포를 의미한다. 따라서 다음과 같은 수식으로 나타낼 수 있다.$$\begin{aligned}a &=\left(a^{(1)}, \cdots, a^{(T-F+1)}\right) \\&=\operatorname{softmax}\left(v_{2}^{\top} \tanh \left(V_{1} H\right)\right)\end{aligned}$$$$V_{1} \in \mathbb{R}^{S \times K} \text { and } v_{2} \in \mathbb{R}^{S}$$
- Feed-forward network 2번 과정의 output은 T-F+1 크기의 vector이므로 바로 FFNN (Feed-forward neural network)의 input으로 사용이 가능하다. FFNN의 역할은 최종적으로 정상과 비정상을 감지하는 것이다. 따라서 최종 layer의 node 개수는 2개이다.
Experiments
FDC 데이터와 SVID 데이터 각각에 대해서 여러 가지 모델을 비교했다.
- SVID : raw data를 그대로 사용
- FDC 1 : 65개의 센서에 대해서 평균과 표준편차만을 이용. (130개 feature)
- FDC 2 : 65개의 센서에 대해서 평균, 표준편차, 최소값, 최대값, 공분산을 이용 (2340개 feature)
FDC data에 대해서는 SVM, RF (random forest), k-NN을 사용했다.
SVM에 대해서만 커널을 linear, raidal basis function 두 개를 사용해 각각 SVM.L, SVM.R 두 가지를 사용했다.
SVID data를 이용한 모델은 Variable-Length Sequence Encoding Methods에서 설명한 4가지 모델과 proposed 모델로 총 5가지이다.
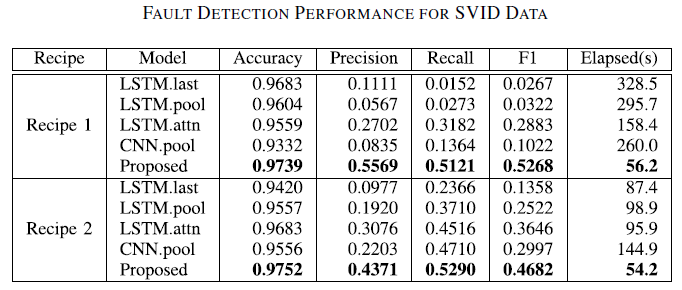
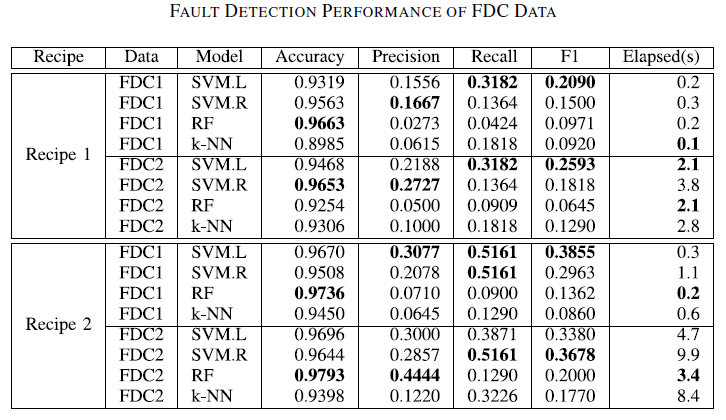
FDC data가 상대적으로 낮은 F1 score를 보였으며 SVID data를 이용한 모델 중에서는 proposed 모델이 가장 좋은 성능을 보였다.
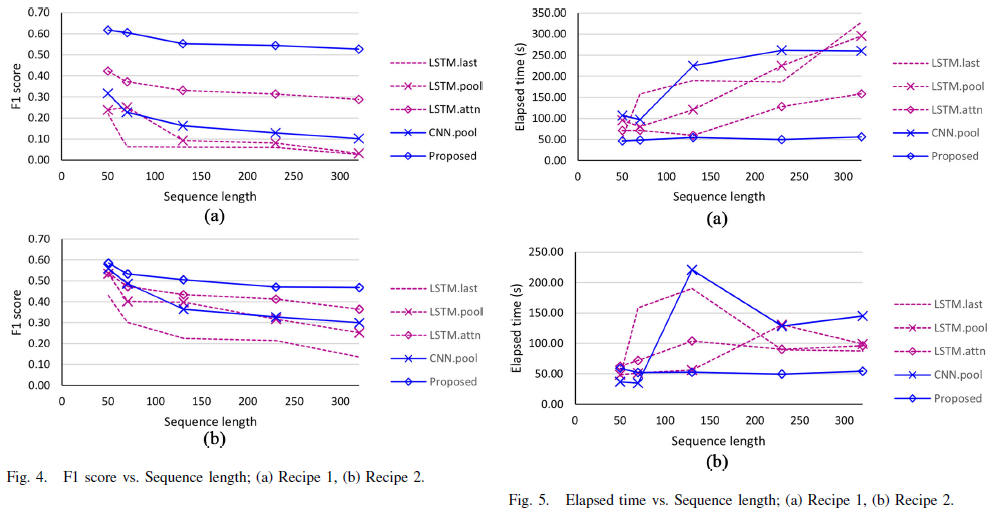
다양한 sequence length에 대해서도 robust하게 높은 성능을 보인다.
다양한 sequence length에 대해서 다른 모델에 비해 일반적으로 적은 시간이 걸리며 비교적 일관된 elapsed time을 보인다.
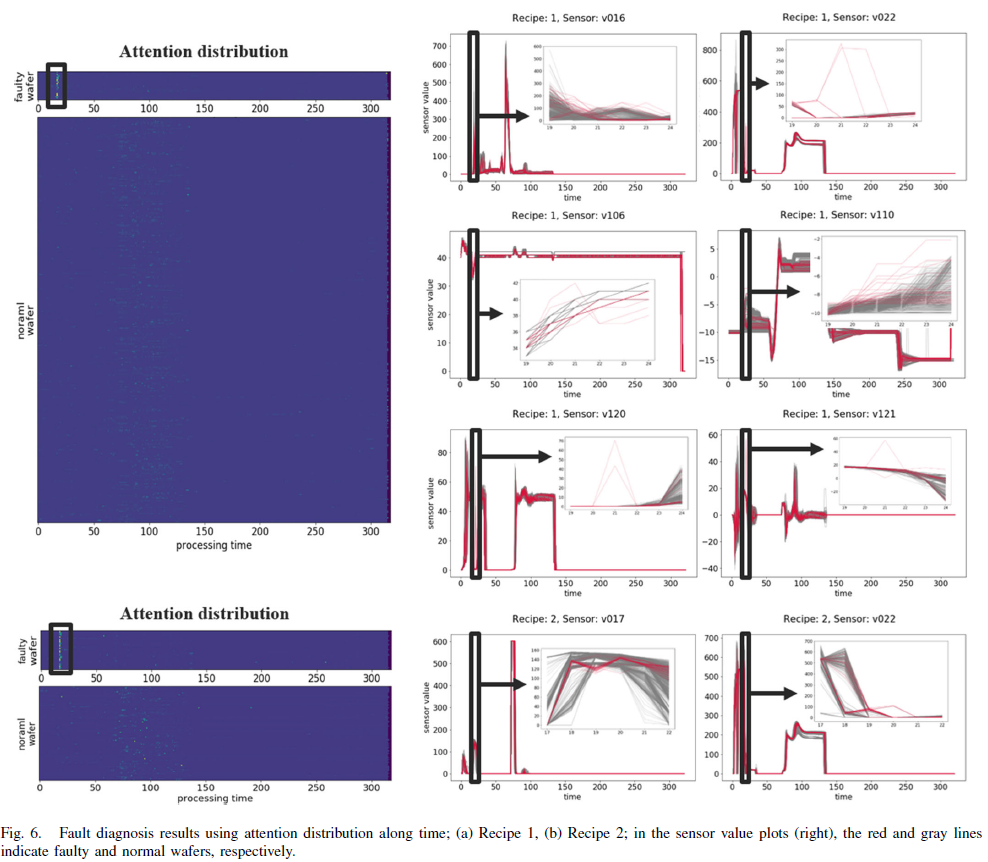
왼쪽의 그림은 attention distribution을 시각화한 것이다. 고장 label인 wafer에 대해서 특정 구간에 다른 분포가 나타남을 확인할 수 있다.
해당 구간은 도메인 전문가들에 의해서 분석한 이상이 발생한 시간과 일치하는 결과를 보였다.
오른쪽 그림은 실제로 이상이 있는 wafer의 시계열 데이터의 일부분이다.
시각적으로 이런 차이가 나타나지만 시계열 데이터의 길이가 너무나 길기 때문에 다음과 같은 이상을 일반적인 방법으로는 찾을 수 없다.
하지만, attention distribution을 이용해 해당 부분을 쉽게 찾을 수 있었다.