1. Introduction
object detection의 복잡성은 물체의 정확한 위치를 찾는 것에서 발생한다.
why ?
1) 너무나 많은 물체의 위치 후보가 처리 되어야 한다.
2) 주어진 위치 후보가 대략적인 위치만을 제공한다. (즉, 정확한 위치를 알기 위해서는 추가적인 작업이 필요하다.)
논문에서는 single-stage training algorithm(object classification & spatial location)을 제안한다.결론적으로, 제안하는 모델은 R-CNN보다 9배 SPPnet보다 3배 빠르며 object proposal 시간을 제외할 경우 이미지당 0.3초의 시간이 소요된다.
1.1 R-CNN and SPPnet
R-CNN은 다음과 같은 단점을 갖고 있다.
1) 학습이 multi-stage pipeline이다.
2) 학습이 시간과 메모리 모두 많이 소모된다.
3) Object detection이 느리다.
R-CNN이 느린 이유는 ConvNet이 각각의 object proposal에 대해서 적용되기 때문이다.SPPnet은 computation sharing을 통해 R-CNN의 단점을 극복하려 했다.
SPPnet
1) 이미지 전체에 대해서 ConvNet을 한 번 거쳐 Feature map을 생성 (computation sharing)
2) object proposal의 위치에 해당하는 1)의 Feature map 영역에서 pooling을 통해 고정된 크기의 output을 추출
3) 2)의 과정을 통해 다른 크기의 output을 여럿 만들고 concat해 분류에 사용
하지만, SPPnet 역시 다음과 같은 단점을 가지고 있다.
1) 학습이 multi-stage pipeline이다.
2) feature를 caching하기 위한 메모리가 필요하다.
3) pooling 이전 단계의 ConvNet을 fine-tuning할 수 없다.
1.2 Contribution
Fast R-CNN의 이점
1) 높은 detection 성능(mAP)
2) Training이 multi-task loss를 사용한 single-stage이다.
3) 학습을 통해 모든 네트워크를 업데이트할 수 있다.
4) caching이 필요없다.
2. Fast R-CNN architecture and training
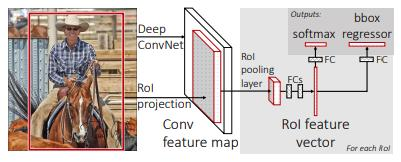
Fast R-CNN 구현 방법
1) 전체 이미지에 대해서 ConvNet + max pooling
2) ROI에 해당하는 feature map에서 일정한 크기의 feature vector를 추출
3) feature vector를 Fully Connected layer
4) 2개의 branch로 output을 보내기
5) softmax : object 각각과 배경인지 여부 분류, bbox regressor : bbox position
2.1 The RoI pooling layer
max pooling을 이용, 주어진 크기의 feature를 생성, pooling은 각 채널에 대해서 개별적으로 적용
2.2 Initializing from pre-trained networks
구현 방법 1)에서 사용된 ConvNet은 ImageNet에서 사용된 pre-trained model을 사용각각은 5개의 max-pooling과 다수의 conv layer를 가지고 있으며 Fast R-Cnn을 위해 다음과 같이 조절함.
1) 마지막 max pooling은 RoI pooling으로 교체
2) 마지막 fully connected layer와 softmax는 2개의 branch로 나눠지게 함.
3) input을 이미지와 bbox 좌표를 받을 수 있게 조절
2.3 Fine-tuning for detection
- Hierarchical sampling
SPPnet에서 각각의 training sample과 sample에 해당하는 다른 크기의 RoI를 매번 이용해 학습하는 것은 매우 비효율적
효율적인 학습 방법을 통해 SPPnet의 세 번째 문제점인 “pooling 이전 단계의 ConvNet을 fine-tuning할 수 없다.”를 해결
효율적인 학습 방법 -> SGD minbatches : N images에 대해서 R/N RoI를 추출하는 방법으로 학습여기서 N을 줄이고 R을 증가시키면 공통된 RoI에 대해서 computation sharing을 할 수 있고 다수의 N에서 소수의 RoI를 이용해서 학습하는 것보다 훨씬 빠른 속도로 학습이 가능하다.
- Multi task loss
- Fast R-CNN의 첫 번째 output은$$p=\left(p_{0}, \ldots, p_{K}\right)$$
K개의 카테고리에 background까지 더한 총 K + 1개의 label에 대한 확률 분포를 가짐.
- 두 번째 output은 $$t^{k}=\left(t_{x}^{k}, t_{y}^{k}, t_{w}^{k}, t_{h}^{k}\right)$$
K-th object에 대해서 bounding box의 정확한 좌표를 유추할 수 있는 4가지 정보를 갖고 있음.
Multi task loss
u : 실제 label
v : 실제 bounding box regression target
λ : 두 loss의 가중치를 조절하는 하이퍼 파라미터
The Iverson bracket indicator function의 경우 [u ≥ 1]이면 1 그렇지 않으면 0논문에서는 배경의 경우 u = 0이 되게 하는 장치
in which
bounding-box regression을 위한 LlocLloc식을 보면smmothL1smmothL1을 이용해 robust한 결과를 도출 (L1 loss는 아웃라이어에 민감하지 않게 반응함.)
일반적인 L2 loss의 경우 gradient exploding을 막기 위해서 learning rate 조절이 매우 중요하지만 robust L1은 zero-mean에서 많이 떨어진 아웃라이어가 들어와도 L2만큼 loss가 크지 않기 때문에 훨씬 robust하다.
- Mini-batch sampling
N = 2, R = 128은 동일,
RoI를 가져오는 기준25% : ground truth 와 IoU값이 0.5이상인 object proposal
75% : ground truth 와 IoU값이 0.1이상 0.5 미만인 object proposal
IoU : 두 영역의 교차영역의 넓이를 합영역으로 나눈 값
IoU가 0.1 미만이면 background로 취급
50% 확률로 horizontal flip 외의 Data augmentation은 사용하지 않음.
- Back-propagation through RoI pooling layers
x_i는 RoI pooling layer의 input에 해당하는 픽셀들의 index를 의미.r번째 RoU의 j번째 index는 다음과 같이 나타날 수 있음.
in which
여기서 R(r,j)는 max pooling의 output이 y_rj에 해당하는 index를 의미
RoI pooling layer은 max pooling의 일종이란 걸 생각하면 쉽게 이해할 수 있을 것이라 생각이 듦
max pooling에서의 back-propagation과 같이 RoI pooling의 back-propagation 식은 다음과 같이 나타낼 수 있다.
- SGD hyper-parameters
weight initialization, training hyperparameter에 대한 설명
2.4 Scale invariance
1) brutal-force approach학습과 테스트 모두 정해진 크기의 픽셀로 이미지 전처리
2) multi scale approach

image pyramid를 이용training 동안에 image pyramid에서 이미지를 랜덤하게 추출 -> 일종의 data augmentation일 수 있다고 함.test 시에 image pyramid를 통해 scale-normalize 진행approximate scale invariance를 제공
3. Fast R-CNN detection
3.1 Truncated SVD for faster detection
image classification의 경우 fully connected layer가 forward pass 소비 시간에서 차지하는 비중이 적음.detection의 경우 fully connected layer가 차지하는 시간 비중이 약 45%에 육박함.truncated SVD를 통해서 이를 어느정도 해결할 수 있음.