Attention based dropout layer for weakly supervised object localization
06 Sep 2020
Reading time ~4 minutes
이번 리뷰를 보기 전에 CAM과 Grad-CAM을 먼저 본다면 더 이해가 원활할 것이다.
CAM
Grad-CAM
Introduction
Weakly supervised object localization은 물체의 위치에 대한 label은 없지만 물체의 종류에 대한 label만 있는 상황에서 분류와 localization을 동시에 할 수 있는 모델을 개발하는 것을 목표로 한다.
Weakly supervised object localization의 대표적인 방법인 CAM과 Grad-CAM은 물체를 구별하는데 가장 큰 영향을 끼친 most discriminatibe 지역을 찾음으로써 localization을 행한다. 하지만 이번 논문에서는 이런 방법론이 갖는 한계를 설명하는데 most discriminative part에만 집중하게 되면 물체의 전체적인 모양을 포함한 localization을 할 수가 없다는 것이다.
논문에서 말하는 재밌는 예는 사람이 label로 있을 때 사람이 입고 있는 옷이 계속 바뀐다면 discriminative 방법으로는 사람의 신체를 discriminative part로 찾을 수가 없을 거라는 것이다. 이미지에서 가장 discriminative한 부분인 얼굴부분만을 highlight하게 될 것이고 이는 우리가 일반적으로 사람이라고 생각하는 머리, 팔, 다리를 포함한 localization과는 거리가 있게 된다.
discriminative part에만 집중하는 방법론의 위와 같은 한계로 인해 최근에는 모델 학습 시에 most discriminative part를 0으로 바꿈으로써 해당 부분에 모든 집중이 가는 것을 막는 방법이 도입되고 있다. 이런 기법은 어떻게 보면 Neural network에서 dropout이 작동하는 방식과 유사하다고 생각될 수 있다.
방금 말한 zero masking 방법을 통해서 discriminative 방법론의 한계를 극복하는 것에는 성공했으나 이런 방법에는 새로운 단점을 하나 갖고 있다. most discriminative한 부분을 찾기 위해 re-train 과정을 여러 번 반복해야 했으며 모델에 추가적인 network를 구축해야 했다. 결과적으로 모델의 계산량이 너무 많아지는 부작용이 생겼다.
Main concept
Introduction에서 본 문제점들을 해결할 수 있는 ADL 모델을 제안한다. 이번 모델에서 가장 중요한 두 개념인 Attention과 Dropout에 대해서 먼저 짚고 넘어가자.
Dropout
일반적으로 dropout은 neural network에서 overfit을 막기 위한 regularization 기법 중 하나로 사용된다. training 동안에 확률적으로 hidden node의 weight을 0으로 바꾸기만 하면 되기 때문에 적용이 매우 쉬운 기법이다.
하지만, 이런 간단한 Dropout을 CNN에 적용할 경우 약간의 문제가 발생한다. CNN은 grid 형태의 공간적 특성을 갖고 있는데 임의로 dropout을 적용하게 되면 grid 내부의 특정 pixel에서 공백이 생기게 되며 애써 만든 공간적 정보를 잃는 일이 발생한다.
이런 문제를 해결하기 위해서 나온 방법이 SpatialDropout이다. 이 방법은 pixel 단위로 dropout을 실행하는 게 아닌 채널 단위로 dropout 을 실행한다.
CNN에서 dropout의 성능을 개선하는 또 다른 dropout 방법은 MaxDrop이다. 가장 큰 value를 갖는 값을 0으로 바꾸는 것인데 원저자의 논문의 그림을 통해서 쉽게 이해할 수 있다.
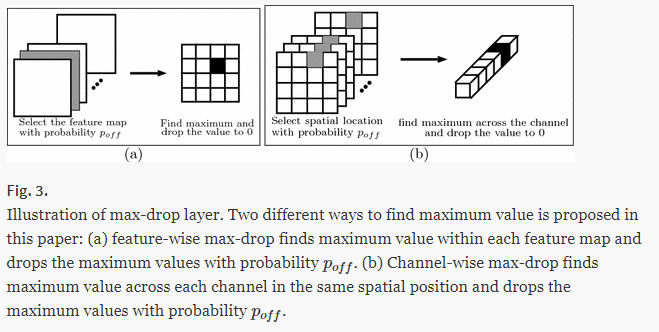
Attention mechanism
예전에 읽었던 Attention is all you need 논문을 다시 한 번 읽고 노션에 정리를 해야할 것 같다. 우선은 Self-attention에 대해서 안다고 생각하고 글을 진행할 생각이다.
최근에 가장 많은 분야에서 널리 쓰이는 개념이라고 하면 Self-attention일 것이다. CNN을 이용한 이미지 분류 문제에서 역시 Attention 개념을 도입하려는 시도가 많았다. CNN에서 Attention mechanism의 도입은 Attention score를 측정하는 축의 방향에 따라 나눌 수 있을 것이다.
Residual Attention Networks (RAN)의 경우, 분류 성능을 높이기 위해 3D self-attention map을 사용한다. 하지만 , 어떤 압축도 없이 3D의 attention score를 구하기 위해서는 많은 parameter들이 새로 추가되어야 하기 때문에 많은 계산량을 요구한다.
Squeeze-and-Excitation Networks (SENet)의 경우 1D channel self-attention map을 이용한다. Global average pooling을 통해서 먼저 데이터를 압축을 시킨 후 2-layer MLP를 통해 self-attention map을 추출한다. RAN에 비해 추가되는 parameter의 수가 10% 정도로 획기적으로 줄이기는 했지만 여전히 많은 계산량을 요구한다.
위의 두 개와는 다른 색다른 Attention-map 계산 방법은 예전에 리뷰했었던 CBAM 논문에 나온다. CBAM은 채널 방향 1D attention과 spatial 2D attention을 순차적으로 적용한 방법이다. 더 자세한 내용은 아래의 링크를 참조하자.
(예전에 리뷰했던 논문들을 링크할 일이 생기니 뿌듯하다:)
ADL: Attention-based Dropout Layer
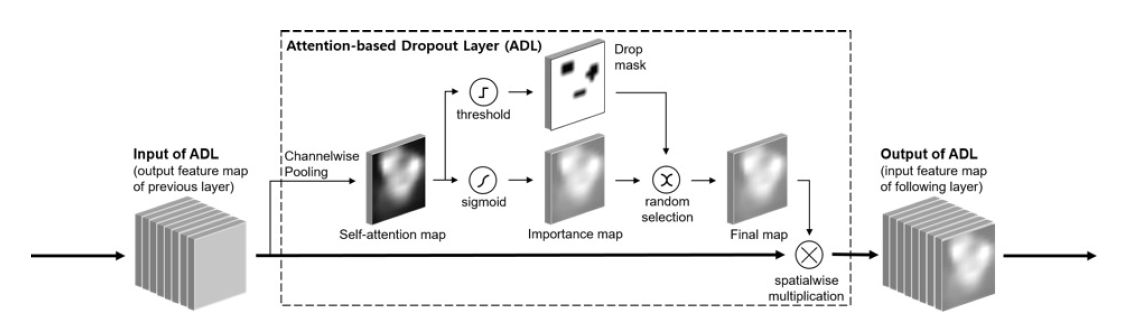
- input이 들어오면 Global average pooling을 이용해 self-attention map을 계산한다.
-
Self-attention map을 이용해 Drop mask와 Importance map을 계산한다.
Drop mask
training 시에 most discriminative part 부분에 0을 곱함으로써 해당 영역에 페널티를 주는 역할을 한다. most discriminative가 아닌 부분에도 모델이 집중할 수 있게 함으로써 물체의 전체적인 구조를 loacalization할 수 있게 도와준다. Drop mask를 통해 제거할 부분은 self-attention map에서 threshold 값을 통해 구한다.
Importance map
모든 iteration에서 Drop mask를 적용한다면 모델은 most discriminative part를 전혀 이용하지 않고 이미지 분류를 하게 된다. 이는 분류 성능 자체에 악영향을 주게 된다. Importance map을 이용해 informative region을 강조함으로써 모델의 분류 성능을 향상시킬 수 있다.Importance map은 self-attention map에 시그모이드를 취함으로써 구할 수 있다.
- Drop mask와 Importance map을 확률적으로 선택한 후, input과 spatialwise multiplication을 통해 output을 계산한다.
모델의 구조를 보면 ADL의 구조는 생각이상으로 많이 단순하다. 이런 단순성이 이번 모델의 최고 장점이기는 하지만 이렇게 단순한데 어떻게 좋은 성능을 보이는지 의문이 아닐 수가 없다. 저자들 역시 이런 궁금증이 생길 것을 알고 있었고 몇 가지 질문에 대해서 답을 논문에서 하고 있다.
Q : Global average pooling 만으로 Self-attention map을 계산하는 것이 가능한 이유는 뭘까?
A : 만약 Global average pooling을 한 map이 충분한 attention 정보를 포함하지 못한다 하더라도 학습 과정에서 CNN의 feature map이 이런 정보를 갖는 방향으로 학습이 될 것이다. 사용하는 CNN 모델의 complexity가 충분히 크기 때문에 CNN의 output feature map이 충분한 attention 정보를 포함할 수 있다고 본다.
Q : Drop mask와 Importance map이 mutually exclusive한 관계이지 않은가?
A : Importance map이 더 정확한 informative region을 학습할수록 Drop mask가 잡는 masking 영역이 most discriminative part일 확률도 높아진다. 따라서 Importance map의 성능 향상이 Drop mask의 역할을 억제하지는 않는다.
Experiments

CAM과 비교했을 때 확실히 물체의 전체 구조를 highlight함을 알 수있다.
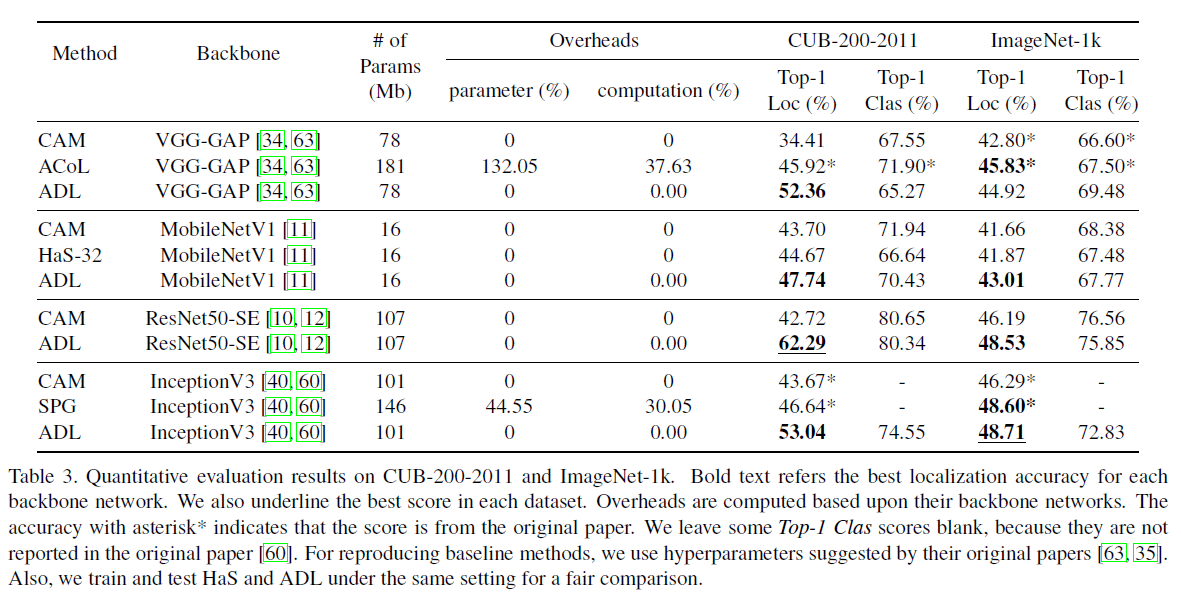
파라미터의 수가 증가하지 않으면서 Localization 성능을 확보할 수 있다는 것은 ADL 모델의 가장 큰 장점으로 보인다.