Boosting Ensemble에 대한 기본적인 이해는 아래의 페이지를 보면 좋습니다.
AdaBoost
Sample마다 Error에 기여하는 정도를 정의하고 Sample Weight을 변화시켜 해당 Error가 큰 Sample에 더 잘 적합하는 모델을 생성하는 방법.
AdaBoost algorithm
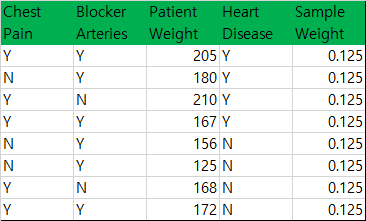
Decision Tree classifier의 예로 풀어서 설명을 한다면
regression의 경우 3. 단계에서 e_m의 정의만 달리하면 똑같은 과정으로 풀 수 있음.
- Sample이 m개 존재한다고 할 때, 모든 Sample Weight을 1/m로 초기화. (m = 8)
- Weak classifier를 다수 생성. Tree에서는 Stump를 이용.

Stump is a decision tree with one internal node (the root) which is immediately connected to the terminal nodes (its leaves). Weak classifier에서 오분류된 Sample의 Sample Weight을 합한 이후, 합이 가장 작은 Weak classifier를 선정.

Chest Pain, Blocker Arteries, Patient Weight 각각에 대해 Stump 생성 후, 가장 낮은 Sample Weight합을 가진 Patient Weight Stump를 선택
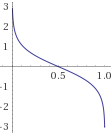
- Amount of say (α_m)을 계산. $$\alpha_{m}=\frac{1}{2} \ln \left(\frac{1-\mathrm{e}_{\mathrm{m}}}{\mathrm{e}_{\mathrm{m}}}\right)$$
(e_m은 3에서 정한 Weak classifier의 Sample Weight합과 동일)
α_m과 e_m은 다음과 같은 관계를 가짐.
- Weak classifier가 맞추지 못한 Sample에 대해서 아래 식을 통해서 Sample Weight을 증가시키고 $$w_{i}^{(m+1)}=w_{i}^{(m)} \mathrm{e}^{\alpha_{m}}=w_{i}^{(m)} \sqrt{\frac{1-e_{m}}{e_{m}}} \\$$
맞은 Sample에 대해서는 아래 식을 통해 Sample Weight을 줄여주는 작업을 진행.
$$w_{i}^{(m+1)}=w_{i}^{(m)} \mathrm{e}^{-\alpha_{m}}=w_{i}^{(m)} \sqrt{\frac{e_{m}}{1-e_{m}}}$$
- 변경된 Sample Weight을 기준으로 weighted random sampling을 통해서 m개의 데이터를 sampling
- 새로운 m개의 Sample에 대해서 다음 종료 조건을 만족할 때 까지 1.~ 5. 과정을 반복.
종료 조건
1) 미리 정한 max n_estimator를 초과할 경우
2) e_m이 0이 될 경우
- 예측 : α_m의 합이 가장 큰 class로 분류